

SSAFY FORCE 프로젝트를 진행하며 발생했던 백엔드 서버와 AWS Lambda로 개발한 크롤링 서비스 간의 트러블 슈팅 과정입니다.
외부 웹사이트를 크롤링하는 서비스를 위해 크롤링에 편리한 라이브러리가 풍부한 Python으로 크롤링 서비스를 개발했습니다. 하지만 메인 백엔드를 Java Spring Boot로 구축했기 때문에 크롤링 서비스를 분리하기로 결정했습니다.
크롤링 서버를 Flask나 FastAPI로 구축할 수도 있었지만, 다음과 같은 이유로 AWS Lambda를 이용하여 서비스하기로 했습니다.
•
인프라 관리 부담 감소: 서버 프로비저닝, 운영체제 업데이트, 보안 패치 등의 관리 작업 불필요
•
확장성 및 탄력성: 트래픽이 증가하면 자동으로 확장되어 안정적인 서비스 제공 가능
•
비용 효율성: 실제 실행 시간에 대해서만 비용을 지불하는 종량제 방식
•
AWS 서비스 통합: CloudWatch, IAM 등 다른 AWS 서비스와의 원활한 연동
문제 상황
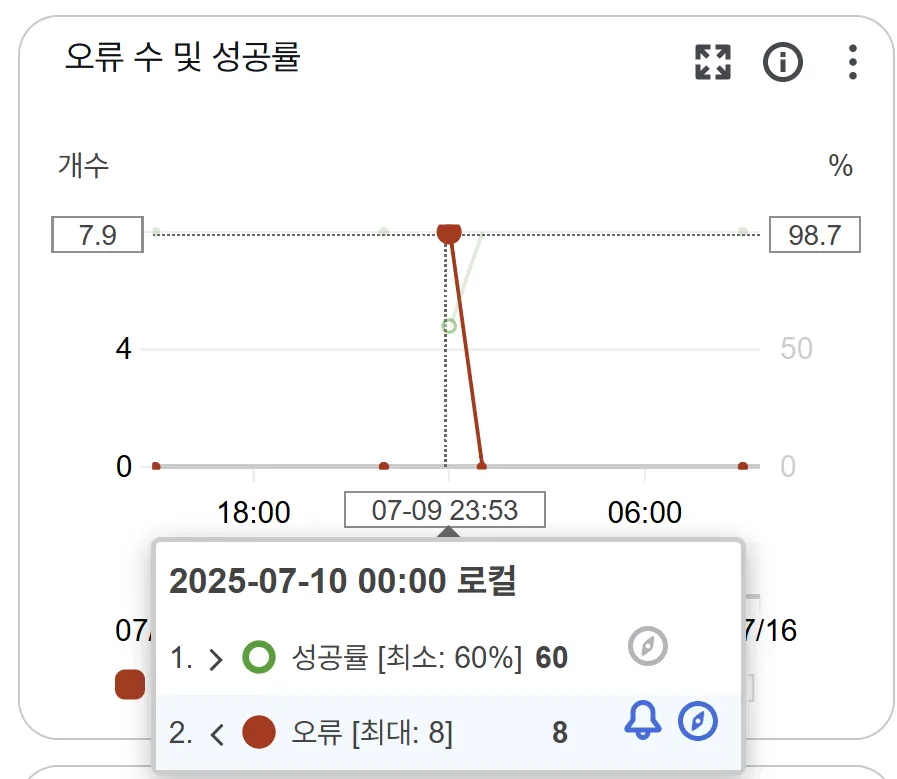
특정 유저들의 해결한 문제를 크롤링하여 가져올 때 실패하는 문제가 있었습니다. 성공하는 유저와 실패하는 유저의 특징을 비교해보니 크롤링해야하는 데이터의 양이 많은 경우 실패하고 있음을 확인했습니다. 크롤링 서비스인 AWS Lambda 서비스에 로깅을 담당하는 CloudWatch에서 로그를 확인해보니, 크롤링 시간이 AWS Lambda의 기본 timeout 시간인 3초를 넘으니 실패함을 확인할 수 있었습니다.
해결 과정
1. 람다 함수의 기본 제한 확장
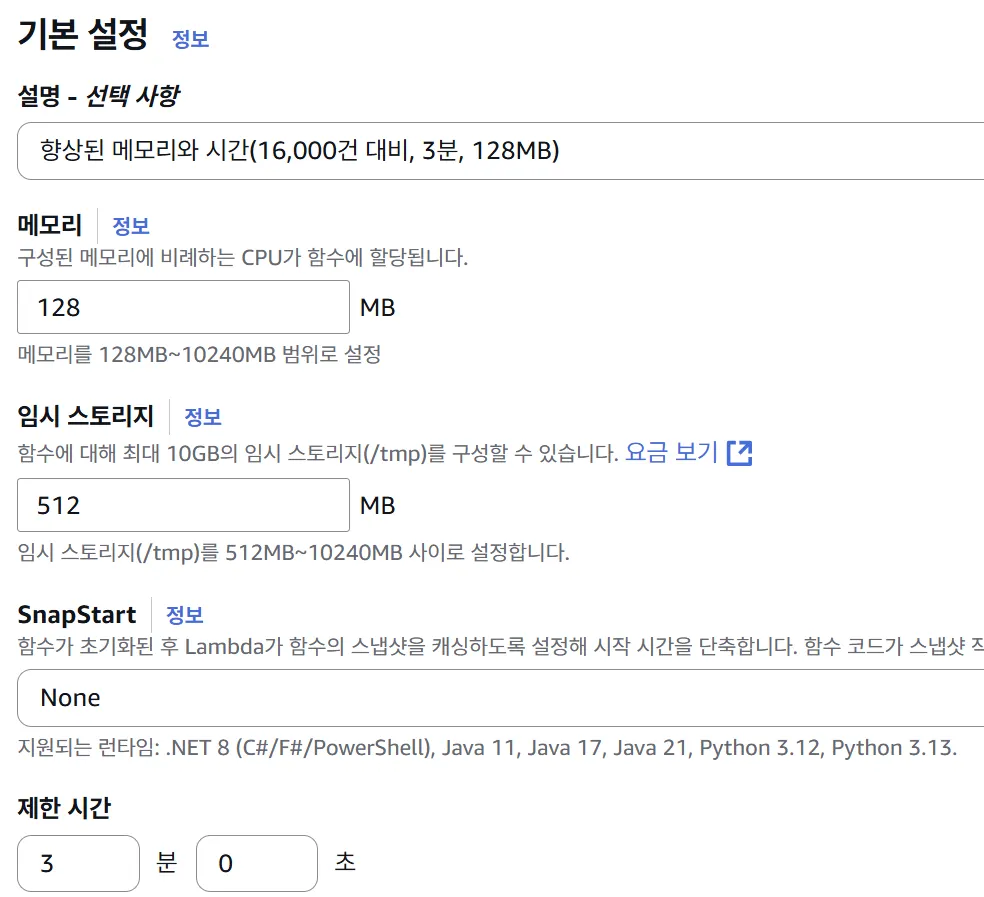
먼저, AWS Lambda 서비스의 기본 제한시간과 기본 메모리 크기를 늘렸습니다. 기본 제한시간인 3초동안 크롤링한 약 200개의 문제를 크롤링하여 최대 크롤링 제한 개수가 10,000건을 넘지 않는다는 가정하에 180초로 늘렸습니다.
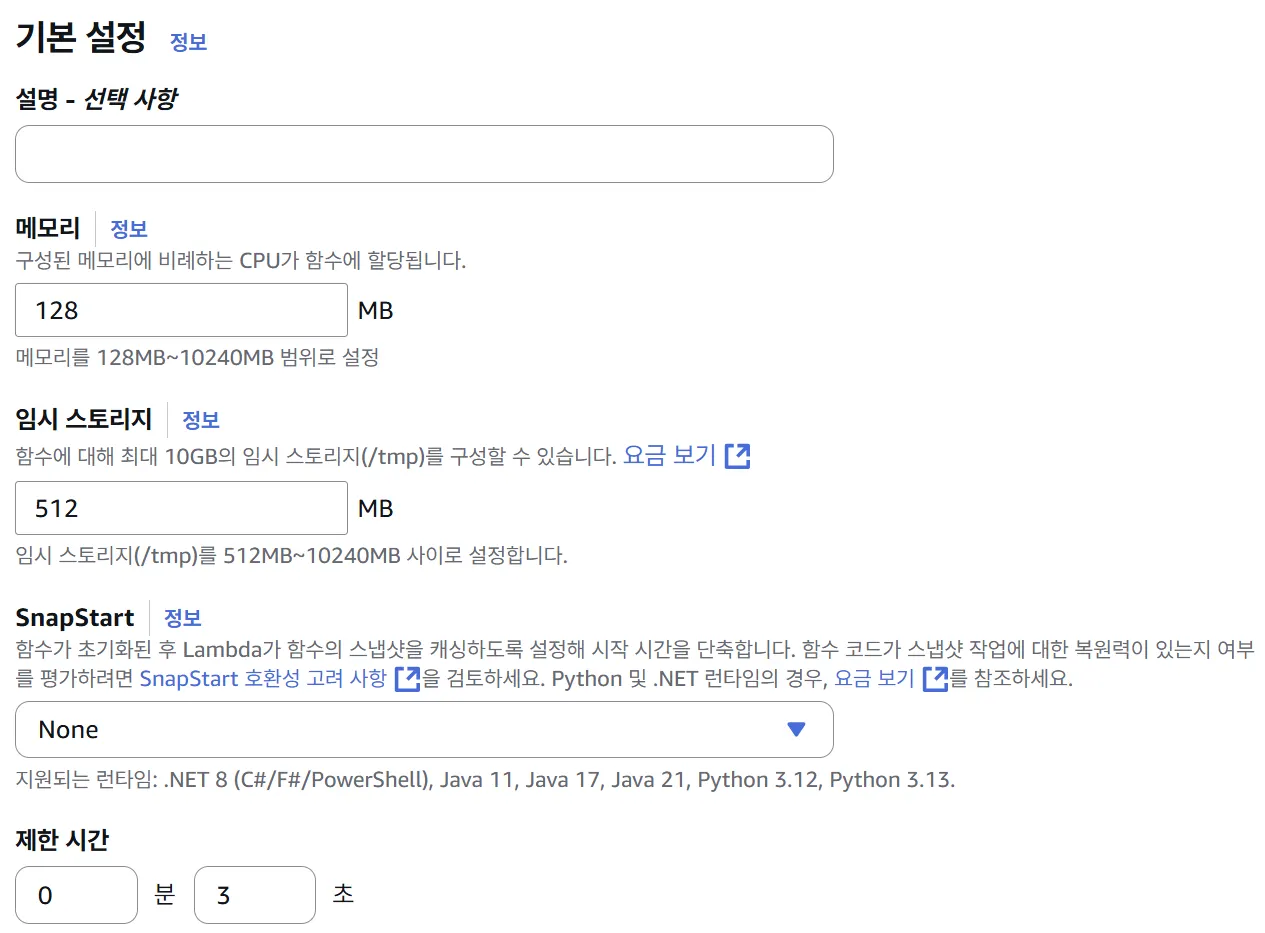
람다함수 기본스펙
•
기본 메모리 : 128 MB
•
임시 스토리지 : 512 MB
•
제한시간 : 3초
람다함수 향상
•
기본 메모리 : 128 MB
•
임시 스토리지 : 512 MB
•
제한시간 : 180초
2. API Gateway
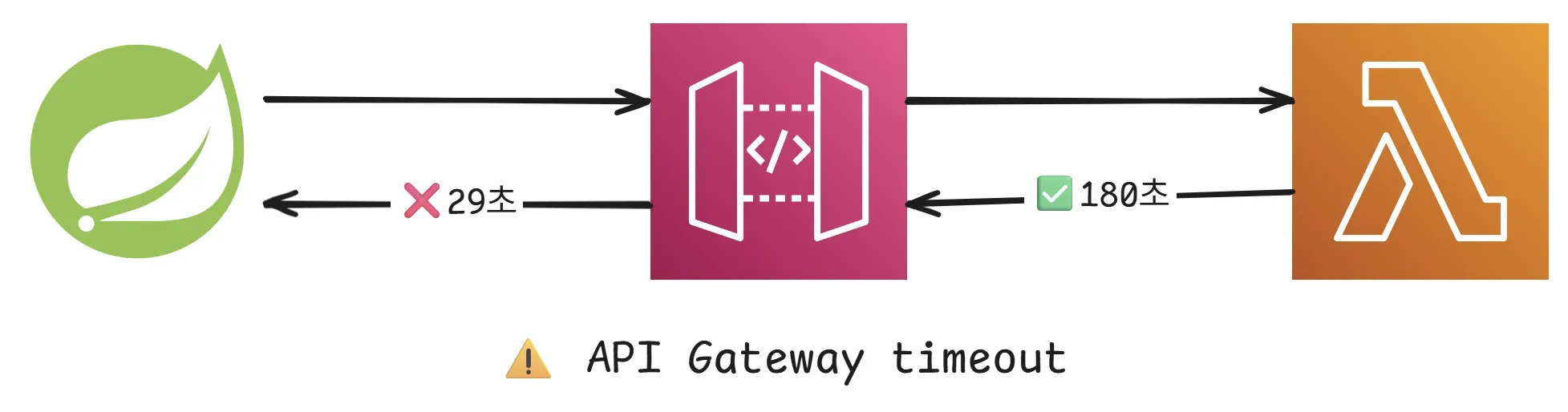
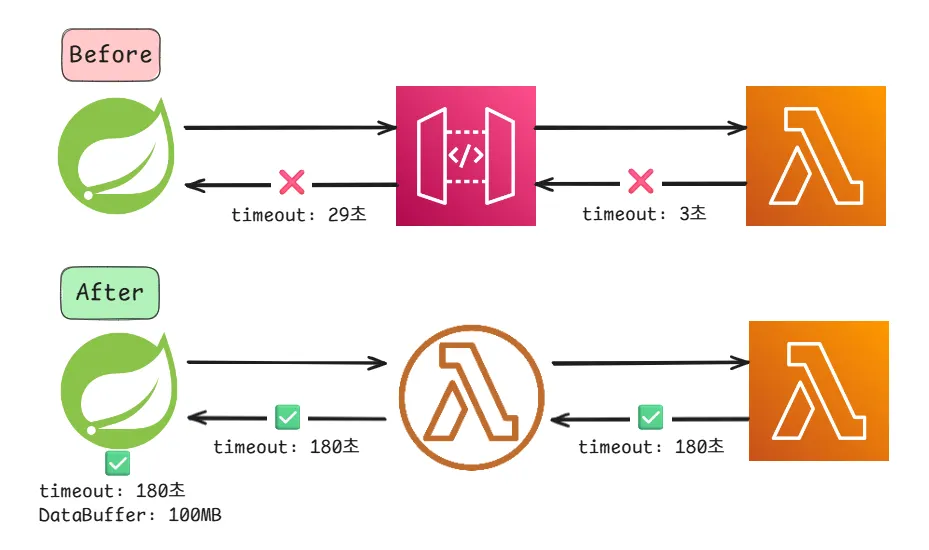
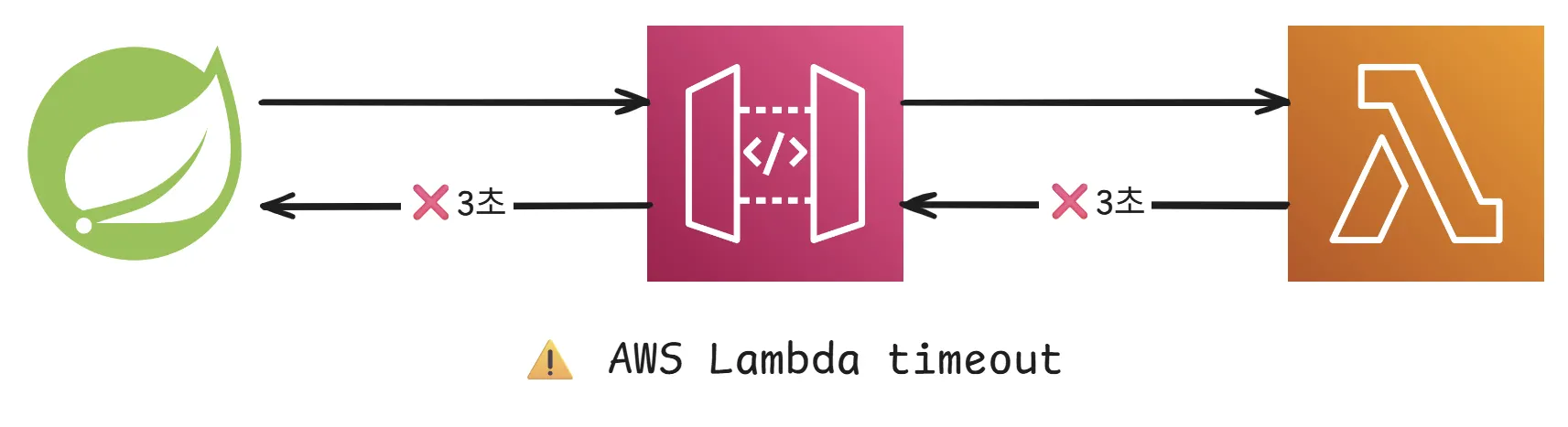
하지만 여전히 크롤링에 실패하였습니다. 로그를 분석해보니 30초 정도 크롤링을 지속하다가 실패함을 확인할 수 있었습니다. 백엔드에서 람다함수를 REST API 방식으로 접근하기 위해서 중간에 둔 AWS API Gateway 서비스에 문제가 있음을 알게 되었습니다. AWS API Gateway의 최대 타임아웃인 29초로 인하여 Lambda 함수의 시간제한을 활용할 수 없었습니다. Lambda 함수의 시간제한을 활용할 수 있는 Lambda Function URLs를 사용하여 시간 문제를 해결할 수 있었습니다.
AWS API Gateway는 일반적인 웹 API 응답 시간을 고려해 최대 타임아웃을 29초로 제한하고 있습니다. 이는 웹 브라우저나 클라이언트가 너무 오래 기다리지 않도록 하는 안전장치 역할을 합니다.
•
기존 트리거 : API Gateway
•
개선된 트리거 : Lambda Functions
3. webFlux의 시간 & 용량 제한
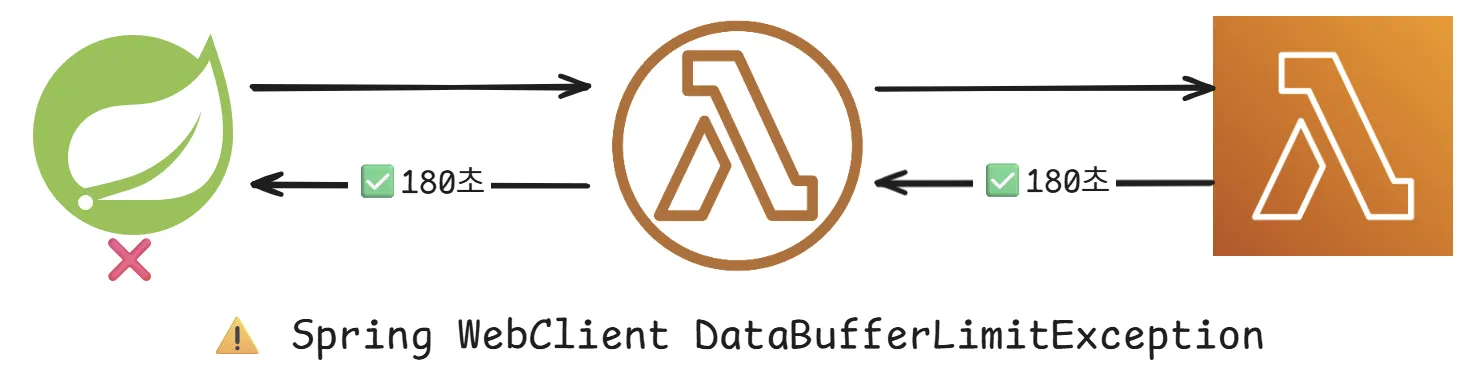
AWS 서비스를 이용하는 부분에 대해서는 문제가 해결되었는데, 백엔드 내부에서 문제가 발생하였습니다. DataBufferLimiatException 으로 인하여 크롤링한 데이터를 전송받지 못하는 상황이였습니다.

DataBufferLimitException: Exceeded limit on max bytes to buffer : 262144
Plain Text
복사
webClient의 기본 메모리 버퍼를 100MB로 넉넉하게 늘리고, Lambda에서 설정한 최대 타임아웃 시간인 180초도 적용 하였습니다.
•
maxInMemorySize(100 * 1024 * 1024)
•
timeout(Duration.ofMinutes(3))
private List<SolvedProblemDto> callLambdaFunction(Map<String, Object> request) {
try {
WebClient webClient = WebClient.builder()
.baseUrl(lambdaUrl)
.codecs(configurer ->
configurer.defaultCodecs().maxInMemorySize(100 * 1024 * 1024)
)
.build();
String response = webClient.post()
.bodyValue(request)
.retrieve()
.bodyToMono(String.class)
.timeout(Duration.ofMinutes(3))
.doOnSubscribe(subscription -> log.info("요청 전송 완료, 응답 대기 중..."))
.doOnNext(resp -> log.info("Lambda 응답 수신 완료 - 크기: {} bytes ({} KB)",
resp.length(), resp.length() / 1024))
.block(); // String자료형을 위한 동기 통신
// 응답 파싱 및 오류 처리
return parseLambdaResponse(response)
} catch (WebClientResponseException e) {
log.error("람다 함수 호출 실패 - HTTP 오류코드: {}, 오류 내용: {}", e.getStatusCode(), e.getMessage());
handleLambdaError(e);
return new ArrayList<>();
} catch (Exception e) {
log.error("람다 함수 호출 실패: {}", e.getMessage(), e);
// 네트워크 오류나 기타 예외 시 RuntimeException으로 래핑
throw new RuntimeException("람다 함수 호출 중 오류가 발생했습니다: " + e.getMessage(), e);
}
}
Java
복사
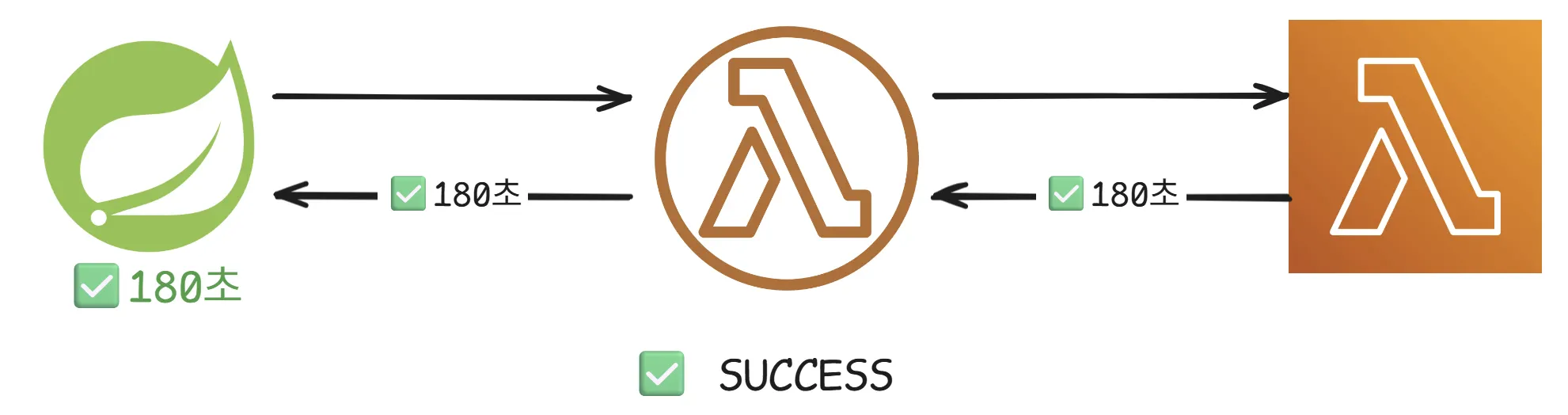

3. 마무리


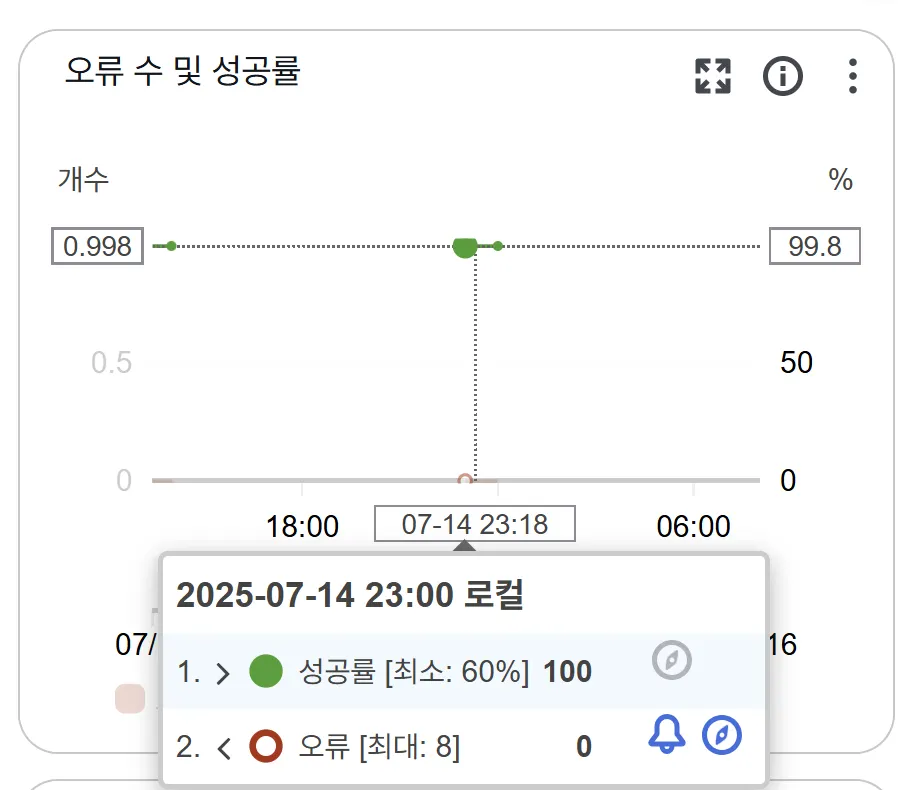
AWS 서비스를 사용하면 로깅기능(AWS CloudWatch)을 제공 해주어서 문제 해결에 도움을 많이 받을 수 있었던 것 같습니다. 크롤링에 실패했는지를 먼저 의심해 Python 코드에도 실패 가능한 지점에 로깅을 위한 출력문을 적으니 CloudWatch에서 확인해볼 수 있었습니다.
크롤링이 오래 걸리는 시점은 문제를 많이 푼 유저가 회원가입을 하여 이때까지 해결한 문제를 모두 크롤링해야하는 시점이였는데, 3분씩 크롤링에 시간을 소요하면 지금의 동기 통신 작업에서 자바 백엔드 스레드를 비효율적으로 쓰는 점은 추후 개선이 필요할 것 같습니다. 또한 타임아웃을 3분으로 향상하는 방법을 사용하였지만 다른 방식을 고민하여 크롤링해야하는 양이 아무리 많아도 해결할 수 있는 방법을 찾아볼 필요가 있습니다.
